When Google Sneezes, the Whole World Catches a Cold

TL;DR Google Cloud's global IAM service glitched at 10:50 AM PT, causing authentication failures across dozens of GCP products. Cloudflare's Workers KV which depends on a Google hosted backing store followed suit, knocking out Access, WARP and other Zero Trust features. Anthropic, which runs on GCP, lost file uploads and saw elevated error rates. Seven and a half hours later, full mitigations were complete and all services recovered. Let’s unpack the chain reaction.
1. Timeline at a Glance
| Time (PT) | Signal | What We Saw |
|---|---|---|
| 10:51 | Internal alerts | GCP SRE receives spikes in 5xx from IAM endpoints |
| 11:05 | DownDetector | User reports for Gmail, Drive, Meet skyrocket |
| 11:19 | Cloudflare status | “Investigating widespread Access failures” |
| 11:25 | Anthropic status | Image and file uploads disabled to cut error volume |
| 12:12 | Cloudflare update | Root cause isolated to third‑party KV dependency |
| 12:41 | Google update | Mitigation rolled out to IAM fleet, most regions healthy |
| 13:30 | Cloudflare green | Access, KV and WARP back online worldwide |
| 14:05 | Anthropic green | Full recovery, Claude stable |
| 15:16 | Google update | Most GCP products fully recovered as of 13:45 PDT |
| 16:13 | Google update | Residual impact on Dataflow, Vertex AI, PSH only |
| 17:10 | Google update | Dataflow fully resolved except us-central1 |
| 17:33 | Google update | Personalized Service Health impact resolved |
| 18:18 | Google final | Vertex AI Online Prediction fully recovered, all clear |
| 18:27 | Google postmortem | Internal investigation underway, analysis to follow |
Click to expand raw status snippets
11:19 PT Cloudflare: "We are investigating an issue causing Access authentication to fail. Cloudflare Workers KV is experiencing elevated errors."
11:47 PT Google Cloud: "Multiple products are experiencing impact due to an IAM service issue. Our engineers have identified the root cause and mitigation is in progress."
12:12 PT Cloudflare: "Workers KV dependency outage confirmed. All hands working with third‑party vendor to restore service."
2. What Broke Inside Google Cloud
GCP’s Identity and Access Management (IAM) is the front door every API call must pass. When the fleet that issues and validates OAuth and service account tokens misbehaves, the blast radius reaches storage, compute, control planes essentially everything.
Figure 1: GCP status page during the first hour
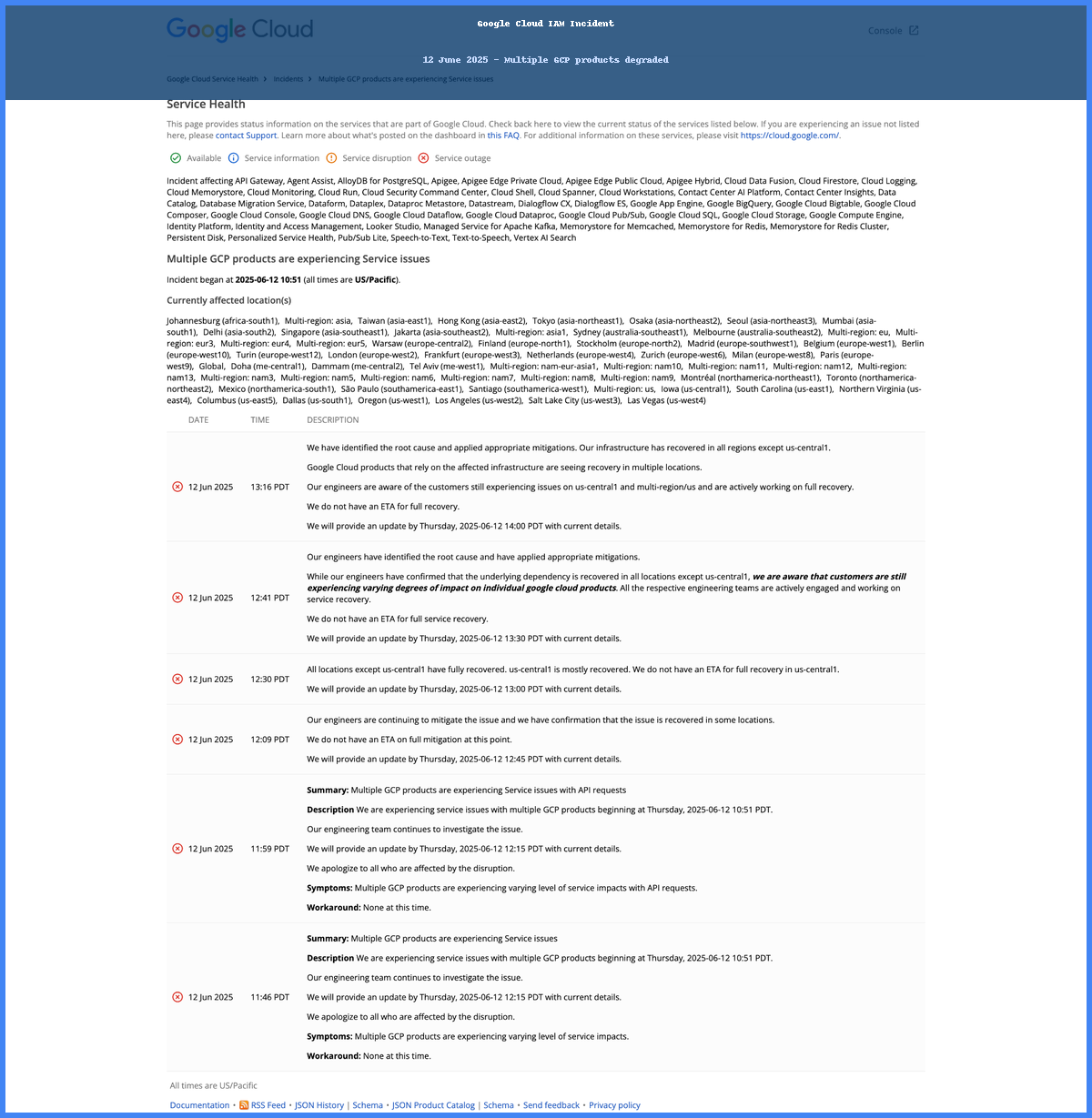
2.1 Suspected Trigger
-
Google’s initial incident summary refers to an IAM back‑end rollout issue indicating that a routine update to the IAM service introduced an error that spread before standard canary checks could catch it.
-
Engineers inside Google reportedly rolled back the binary and purged bad configs, then forced token cache refresh across regions. us‑central1 lagged behind because it hosts quorum shards for IAM metadata.
2.2 Customer Impact Checklist
- Cloud Storage: 403 and 500 errors on signed URL fetches
- Cloud SQL and Bigtable: auth failures on connection open
- Workspace: Gmail, Calendar, Meet intermittently 503
- Vertex AI, Dialogflow, Apigee: elevated latency then traffic drops
3. Cloudflare’s Dependency Chain Reaction
Cloudflare’s Workers KV stores billions of key‑value entries and replicates them across 270+ edge locations. The hot path is in Cloudflare’s own data centers, but the persistent back‑end is a multi‑region database hosted on Google Cloud. When IAM refused new tokens, Writes and eventually Reads to the backing store timed out.
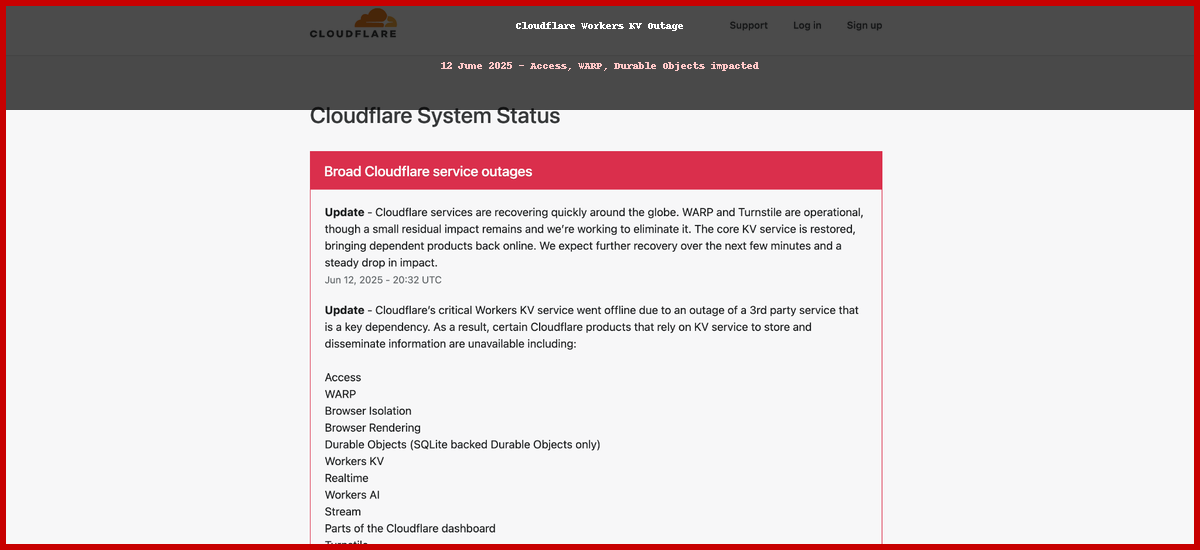
Figure 2: Cloudflare status excerpt highlighting Access, KV and WARP as degraded
3.1 Domino Effects
- Cloudflare Access uses KV to store session state -> login loops
- WARP stores Zero Trust device posture in KV -> client could not handshake
- Durable Objects (SQLite) relied on KV for metadata -> subset of DOs failed
- AI Gateway and Workers AI experienced cold‑start errors due to missing model manifests in KV
Cloudflare’s incident commander declared a Code Orange their highest severity and spun up a cross‑vendor bridge with Google engineers. Once IAM mitigation took hold, KV reconnected and the edge quickly self‑healed.
4. Anthropic Caught in the Crossfire
Anthropic hosts Claude on GCP. The immediate failure mode was file upload (hits Cloud Storage) and image vision features, while raw text prompts sometimes succeeded due to cached tokens.
[12:07 PT] status.anthropic.com: "We have disabled uploads to reduce error volume while the upstream GCP incident is in progress. Text queries remain available though elevated error rates persist."
Anthropic throttled traffic to keep the service partially usable, then restored uploads after Google’s IAM fleet was stable.
5. Lessons for Engineers
- Control plane failures hurt more than data plane faults. Data replication across zones cannot save you if auth is down.
- Check hidden dependencies. Cloudflare is multi‑cloud at the edge, yet a single‑vendor choice deep in the stack still cascaded.
- Status pages must be fast and honest. Google took nearly an hour to flip the incident flag. Customers were debugging ghosts meanwhile.
- Design an emergency bypass. If your auth proxy (Cloudflare Access) fails, can you temporarily route around it?
- Chaos drills still matter. Rare multi‑provider events happen and the playbooks must be rehearsed.
6. Still Waiting for the Full RCAs
- Google will publish a postmortem once internal review wraps expect details on the faulty rollout, scope of blast radius and planned guardrails.
- Cloudflare traditionally ships a forensic blog within a week. Watch for specifics on Workers KV architecture and new redundancy layers.

Figure 3: What every SRE did for two hours straight
7. Updated Analysis: What Google's Official Timeline Tells Us
Google's detailed incident timeline reveals several important details not visible from external monitoring:
8.1 Root Cause Identification
- 12:41 PDT: Google engineers identified root cause and applied mitigations
- 13:16 PDT: Infrastructure recovered in all regions except us-central1
- 14:00 PDT: Mitigation implemented for us-central1 and multi-region/us
The fact that us-central1 lagged significantly behind suggests this region hosts critical infrastructure components that require special handling during recovery operations.
8.2 Phased Recovery Pattern
- Infrastructure Layer (12:41-13:16): Underlying dependency fixed globally except one region
- Product Layer (13:45): Most GCP products recovered, some residual impact
- Specialized Services (17:10-18:18): Complex services like Dataflow and Vertex AI required additional time
8.3 The Long Tail Effect
Even after the root cause was fixed, some services took 5+ additional hours to fully recover:
- Dataflow: Backlog clearing in us-central1 until 17:10 PDT
- Vertex AI: Model Garden 5xx errors persisted until 18:18 PDT
- Personalized Service Health: Delayed updates until 17:33 PDT
This demonstrates how cascading failures create recovery debt that extends far beyond the initial fix.
8. Wrap Up
At 10:50 AM a bug in a single Google Cloud service took down authentication worldwide. Within half an hour that failure reached Cloudflare and Anthropic. By 1:30 PM everything was green again, but not before reminding the internet just how tangled our dependencies are.
Keep an eye out for the official RCAs. Meanwhile, update your incident playbooks, test your failovers and remember that sometimes the cloud’s biggest danger is a bad config on a Tuesday.