Claude Sonnet 4 vs Kimi K2 vs Gemini 2.5 Pro: Which AI actually ships production code?
TL;DR
I tested three AI models on the same Next.js codebase to see which delivers production-ready code with minimal follow-up.
Claude Sonnet 4: Highest completion rate and best prompt adherence. Understood complex requirements fully and delivered complete implementations on first attempt. At $3.19 per task, the premium cost translates to significantly less debugging time.
Kimi K2: Excellent at identifying performance issues and code quality problems other models missed. Built functional features but occasionally required clarification prompts to complete full scope. Strong value at $0.53 per task for iterative development.
Gemini 2.5 Pro: Fastest response times (3-8 seconds) with reliable bug fixes, but struggled with multi-part feature requests. Best suited for targeted fixes rather than comprehensive implementations. $1.65 per task.
Testing Methodology
Single codebase, same tasks, measured outcomes. I used a real Next.js app and asked each model to fix bugs and implement a feature tied to Velt (a real-time collaboration SDK).
- Stack: TypeScript, Next.js 15.2.2, React 19
- Codebase size: 5,247 lines across 49 files
- Architecture: Next.js app directory with server components
- Collaboration: Velt SDK for comments, presence, and doc context
Tasks each model had to complete
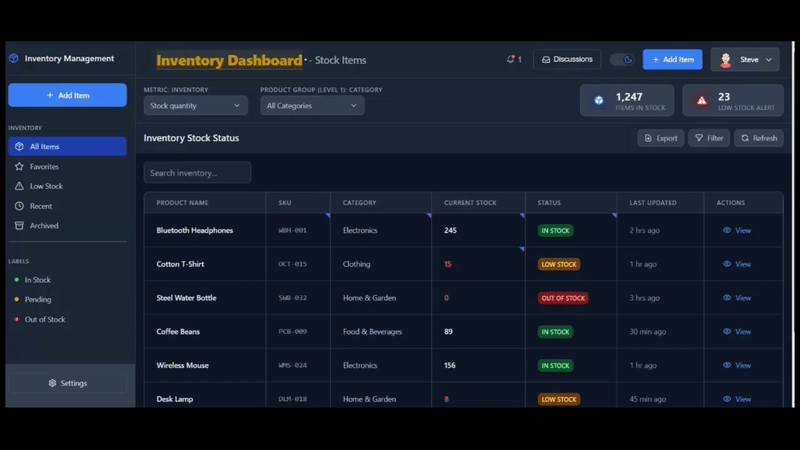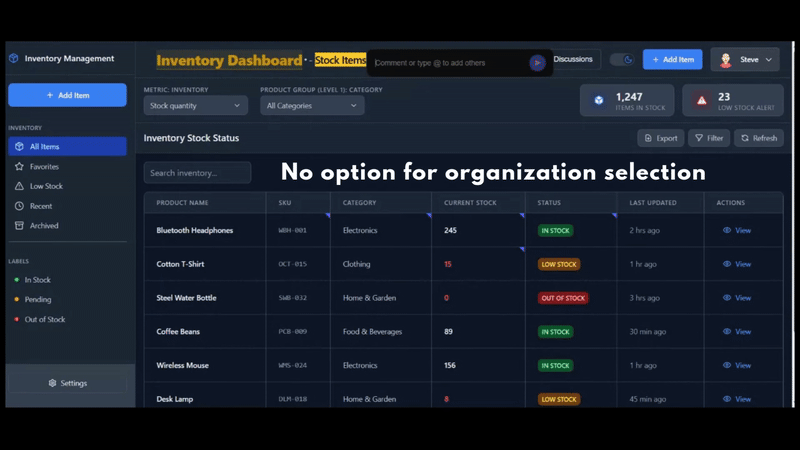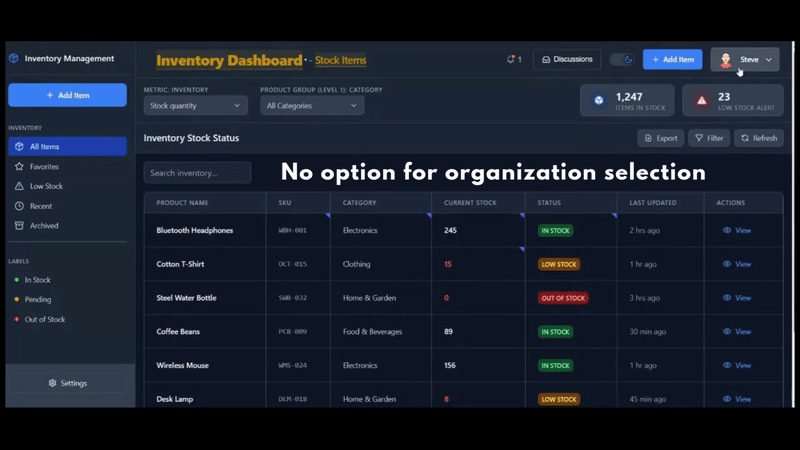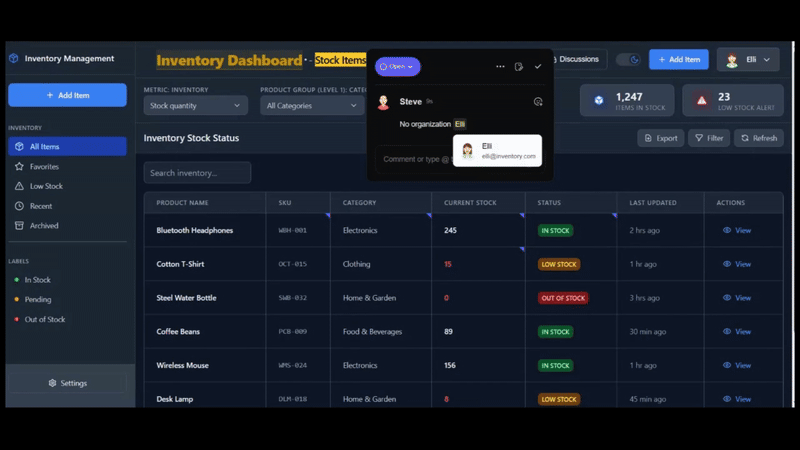
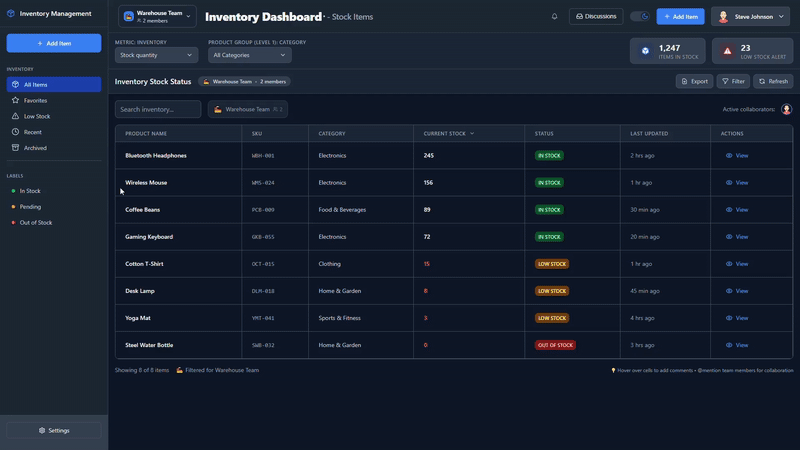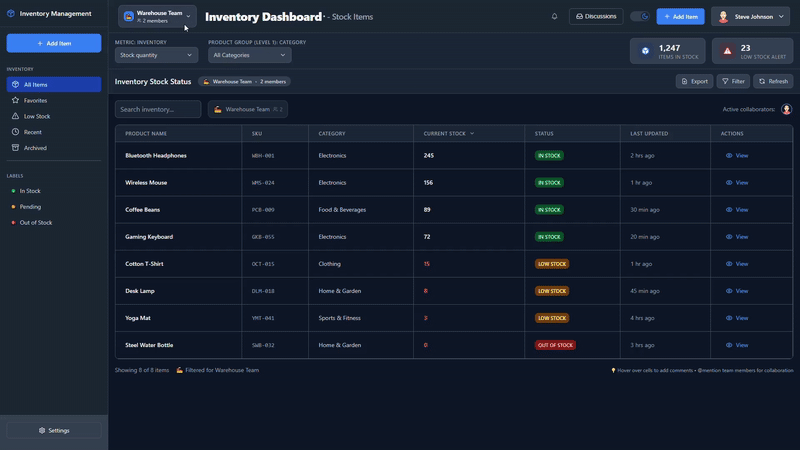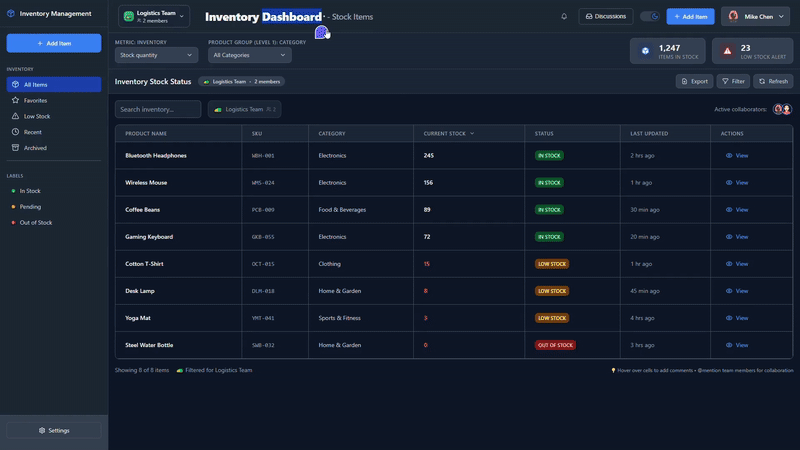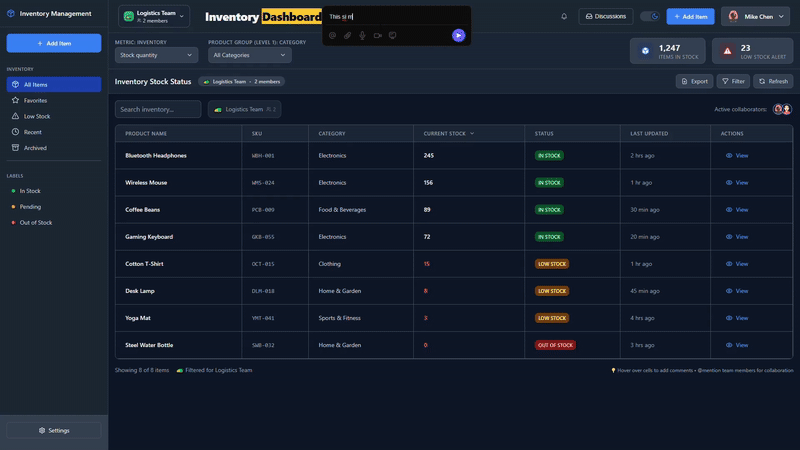
This is the inventory management dashboard I used for testing. Multiple users can comment or suggest changes using Velt in real time.
- Fix a stale memoization issue that caused stale data under certain filter changes.
- Remove unnecessary state causing avoidable re-renders in a list view.
- Fix user persistence on reload and ensure correct identity is restored.
- Implement an organization switcher and scope Velt comments/users by organization ID.
- Ensure Velt doc context is always set so presence and comments work across routes.
Prompts and iterations
All models got the same base prompt:
This inventory management app uses Velt for real-time collaboration and commenting. The code should always set a document context using useSetDocument so Velt features like comments and presence work correctly, and users should be associated with a common organization ID for proper tagging and access. Please review the provided files and fix any issues related to missing document context, organization ID usage, and ensure Velt collaboration features function as intended.
When models missed parts of the task, I used follow-up prompts like "Please also implement the organization switcher" or "The Velt filtering still needs to be completed." Different models required different amounts of guidance - Claude typically got everything in one shot, while Gemini and Kimi needed more specific direction.
Results at a glance
| Model | Success rate | First-attempt success | Response time | Bug detection | Prompt adherence | Notes |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 4/5 | 3/5 | 3-8 s | 5/5 | 3/5 | Fastest. Fixed bugs, skipped org-switch until a follow-up prompt. |
| Claude Sonnet 4 | 5/5 | 4/5 | 13-25 s | 4/5 | 5/5 | Completed the full feature and major fixes; needed one small UI follow-up. |
| Kimi K2 | 4/5 | 2/5 | 11-20 s | 5/5 | 3/5 | Found performance issues, built the switcher, left TODOs for Velt filtering that a follow-up resolved. |
GIFs from the runs:
- Gemini 2.5 Pro
- Claude Sonnet 4
- Kimi K2
Speed and token economics
For typical coding prompts with 1,500-2,000 tokens of context, observed total response times:
- Gemini 2.5 Pro: 3-8 seconds total, TTFT under 2 seconds
- Kimi K2: 11-20 seconds total, began streaming quickly
- Claude Sonnet 4: 13-25 seconds total, noticeable thinking delay before output

Token usage and costs per task (averages):
| Metric | Gemini 2.5 Pro | Claude Sonnet 4 | Kimi K2 | Notes |
|---|---|---|---|---|
| Avg tokens per request | 52,800 | 82,515 | ~60,200 | Claude consumed large input context and replied tersely |
| Input tokens | ~46,200 | 79,665 | ~54,000 | Gemini used minimal input, needed retries |
| Output tokens | ~6,600 | 2850 | ~6,200 | Claude replies were compact but complete |
| Cost per task | $1.65 | $3.19 | $0.53 | About 1.9x gap between Claude and Gemini |
Note on Claude numbers: 79,665 input + 2850 output = 82,515 total. This matches the observed behavior where Claude reads a lot, then responds concisely.
Total cost of ownership: AI + developer time
When you factor in developer time for follow-ups, the cost picture changes significantly. Using a junior frontend developer rate of $35/hour:

| Model | AI cost | Follow-up time | Dev cost (follow-ups) | Total cost | True cost ranking |
|---|---|---|---|---|---|
| Claude Sonnet 4 | $3.19 | 8 min | $4.67 | $7.86 | 2nd |
| Gemini 2.5 Pro | $1.65 | 15 min | $8.75 | $10.40 | 3rd (most expensive) |
| Kimi K2 | $0.53 | 8 min | $4.67 | $5.20 | 1st (best value) |
The follow-up time includes reviewing incomplete work, writing clarification prompts, testing partial implementations, and integrating the final pieces. Gemini's speed advantage disappears when you account for the extra iteration cycles needed to complete tasks.
Analysis: Claude's premium AI cost is offset by requiring minimal developer intervention. Gemini appears cheapest upfront but becomes the most expensive option when factoring in your time.
What each model got right and wrong
- Gemini 2.5 Pro
- Wins: fastest feedback loop, fixed all reported bugs, clear diffs
- Misses: skipped the org-switch feature until prompted again, needed more iterations for complex wiring
- Kimi K2
- Wins: excellent at spotting memoization and re-render issues, good UI scaffolding
- Misses: stopped short on Velt filtering and persistence without a second nudge
- Claude Sonnet 4
- Wins: highest task completion and cleanest final state, least babysitting
- Misses: one small UI behavior issue required a quick follow-up
Limitations and caveats
- One codebase and one author. Different projects may stress models differently.
- I did not penalize models for stylistic code preferences as long as the result compiled cleanly and passed linting.
- Pricing and token accounting can change by provider; numbers reflect my logs during this run.
- I measured total response time rather than tokens per second since for coding the complete answer matters more than streaming speed.
Final verdict
The total cost of ownership analysis reveals the real winner here. While Claude Sonnet 4 has the highest AI costs, it requires the least developer time to reach production-ready code. Kimi K2 emerges as the best overall value when you factor in the complete picture.
For cost-conscious development: Kimi K2 provides the best total value at $5.20 per task. Yes, it needs follow-up prompts, but the total cost including your time is still lowest. Plus it catches performance issues other models miss.
For production deadlines: Claude Sonnet 4 delivers the most complete implementations on first attempt at $7.86 total cost. When you need code that works right away with minimal debugging, the premium cost pays for itself.
For quick experiments: Gemini 2.5 Pro has the fastest response times, but the follow-up overhead makes it surprisingly expensive at $10.40 total cost. Best suited for simple fixes where speed matters more than completeness.
The key insight: looking at AI costs alone is misleading. Factor in your time, and the value proposition completely changes. The "cheapest" AI option often becomes the most expensive when you account for the work needed to finish incomplete implementations.