Kimi K2 vs Grok 4: Which AI Model Codes Better?
The recently released AI model, Kimi K2 from Moonshot AI1, is an open-source model that many consider a viable alternative to Claude Sonnet 4.
I couldn't stop myself from conducting real-world coding tests between Kimi K2 and the recently released Grok 4 model. Both of these models are considered top models for coding, and the result is pretty close. One of the models slightly outperformed the other, as it's said the main test comes from using and testing in a real-world scenario rather than blindly following the synthetic metrics shared about the models.
Testing Methodology and Setup
To keep things real, I've tested both models on an actual, fairly complex Next.js application where I introduced some bugs and asked both of them to fix them, implement a few new features, and see how well they can handle tool calls.
I used the same prompt and test setup for both models, ran each task three times, and picked the best valid result for evaluation. Although I checked each attempt manually, there might still be some subjectivity in scoring, especially for code quality.
The Test App Overview
The application I used for testing is a medium-sized Next.js-based Applicant Tracking System (ATS).
- User authentication using NextAuth.js2
- Semantic search using Pinecone3 as the vector database
- File storage with PDF and DOCX support using AWS
- Admin dashboard to view, filter, and manage applicant profiles
Testing Categories
- Find and fix bugs (5 tasks): The bugs addressed were:
- Stale props in Server Components due to missing
revalidatePath()after a mutation - Broken file upload validation for DOCX files
- Incorrect database pagination logic on the admin dashboard
- A React
useEffecthook that caused infinite re-renders - UI rendering glitch due to improper loading state handling
Each bug was clearly reproducible and included test coverage. The models were asked to fix them without changing unrelated logic.
- Implement new features (4 tasks): The new features developed included:
- A chat agent with tool-calling capabilities using Composio4 MCP
- Dashboard with server-side pagination and filtering
- Dark mode toggle with persistent state
- Add dynamic form validation in user signup
- Code refactor: Improve code structure and readability without breaking any functionality
Evaluation Criteria
- First and foremost, the code must be correct with no logic errors.
- How well the model follows the prompt and stays on task.
- The overall code quality and structure.
- The time taken to complete the given task.
- Finally, one of the most important factors I'll consider is the overall token efficiency.
Code Quality Criteria
I judged the code quality by examining how well each model structured and organized its output. Here are the key factors I considered:
- Modularity: Code organized into reusable functions/components
- Readability: Variable/function naming, comments, and structure
- Maintainability: Presence of unused variables, repeated code
- Testability: Easy to write test cases for the logic
Chat Agent in Action
Prompt: Enhance this Next.js application by building a chat-based AI agent at the
/chatendpoint. Integrate MCP tool-calling using Composio’s v3 SDK, and ensure proper configuration of the MCP client. Show creativity in the UI, and make sure tool call responses are clearly displayed.
Curious how the final agents turned out? Check out the demo below:
- Kimi K2 - Building a Chat Agent
Here's the agent in action:
As you can see, it works perfectly fine. Tool calls with the integrations work great. However, this was not the output on the very first attempt. I had to do some iterations with the prompt to get this result. But it all works, and that's what matters.
- Grok 4 - Building the Same Agent
Here's the agent in action:
This one looks even better in the UI, and the implementation is also better. I ran three attempts for a single task to ensure consistency for both models, and the best part is that it worked perfectly on the very first attempt. Grok 4 pretty much one-shotted this beautiful-looking entire chat agent in a single prompt.
Performance Analysis
The entire test is conducted using our ForgeCode CLI.
Here's the performance comparison between Kimi K2 and Grok 4 across 9 tasks:
Execution Metrics
| Metric | Kimi K2 | Grok 4 | Notes |
|---|---|---|---|
| Avg Response Time | ~11.7-22s | ~10.3-16s | Kimi K2 had a faster first token, but Grok completed responses more quickly overall. |
| Single-Prompt Success | 6/9 | 7/9 | Kimi K2 was close, but Grok 4 usually got it right on the first try. |
| Tool Calling Accuracy | ~70% | 100% | Based on test results (not benchmarks), Grok 4 consistently made structured tool calls correctly, while Kimi K2 was inconsistent. |
| Bug Detection | 4/5 (80%) | 5/5 (100%) | Kimi K2 found edge cases well, but Grok handled code changes much better. |
| Prompt Adherence | 7/9 | 8/9 | Kimi K2 and Grok 4 were both excellent, but Grok felt more on track, while K2 occasionally went off track. |
Test Sample: 9 tasks, repeated 3 times for consistency Confidence Level: High, based on manual verification
Code Quality Breakdown
For each task, code quality was evaluated based on the four factors I mentioned earlier.
| Factor | Kimi K2 | Grok 4 | Notes |
|---|---|---|---|
| Modularity | Needs improvement | Well-structured | Kimi K2 often grouped too much logic together. |
| Readability | Clear and readable | Clear and readable | Both used good naming and structure. Kimi K2 was a bit more verbose. |
| Maintainability | Redundant and unused code | Clean and maintainable | Kimi K2 had redundancy and unused variables in most tasks. |
| Testability | Struggled with isolated tests | Clean and organized test cases | Grok 4 wrote better unit tests. Kimi K2’s issues came from unorganized code. |
Verdict
Overall, both models performed well in my tests. Grok 4, however, had a slight edge as it was more accurate with tool use, detected and fixed more bugs, and consistently produced cleaner code with better test coverage.
Kimi K2 did really well too, but at times it wrote code with many unused variables (I don't know why that is the case, but almost every single task declared some unused variables), had a slight problem with prompt following, and was a bit slower. In short, Grok 4 was a bit more polished, but we can't undermine the fact that Kimi K2 offers great performance at a fraction of the cost of Grok 4, so that's something to consider here.
Speed and Overall Token Usage
When it comes to the response speed of both models, I didn't notice much difference. Both models are quite slow at generating responses. Considering an average coding prompt with about 1,000 tokens, Grok outputs around 50 tokens per second, while Kimi K2 outputs about 47 tokens per second.
Many providers, like Groq5, offer high output speed (tokens per second), but here we're focusing on a standard use case with a typical provider.
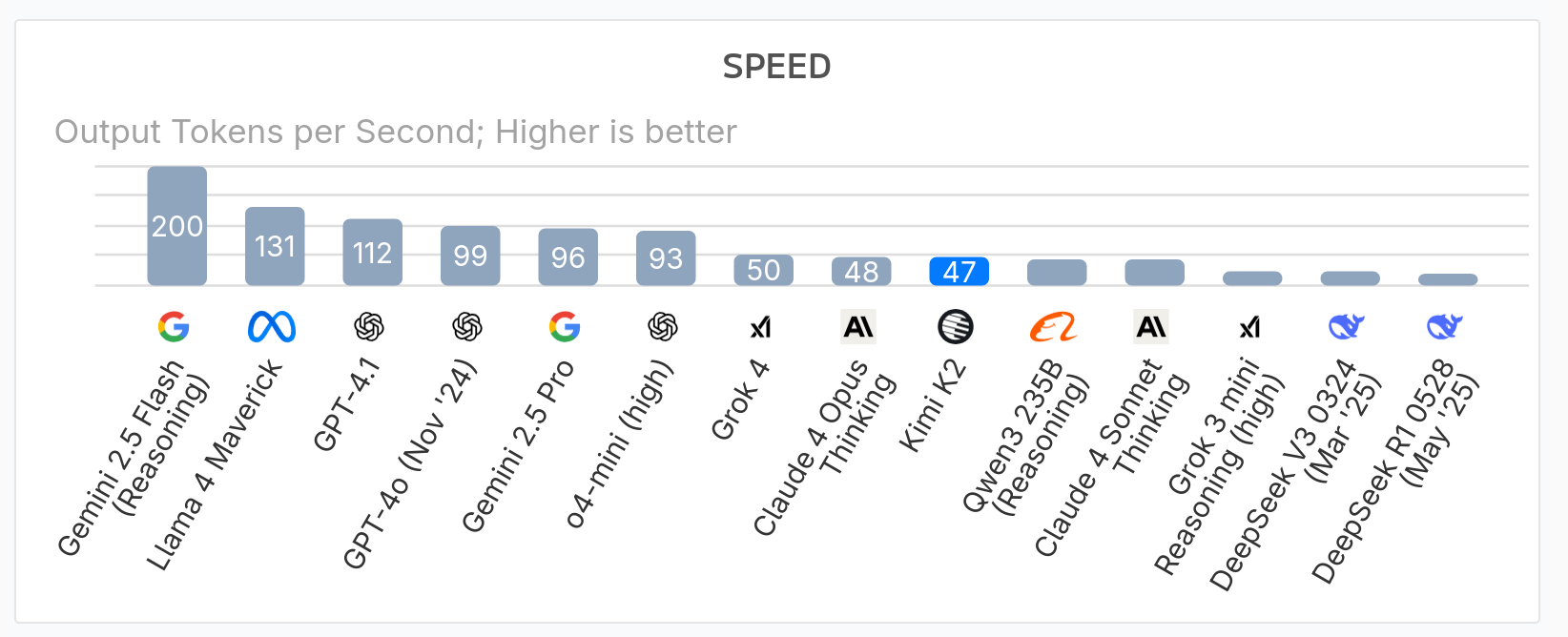
However, if we compare the latency (TTFT - time to first token), Grok 4 has a typical latency of 11-16 seconds for heavier reasoning modes, while Kimi K2 has lower latency, just about 0.52s to receive the first token.
Kimi K2 is a non-reasoning model but uses about three times the tokens of an average non-reasoning model. Its token usage is only about 30% lower than reasoning models like Claude 4 Sonnet and Opus6 when running in maximum budget extended thinking mode.
Now, if we look into the overall token usage in the entire test and in general, Grok 4 consumed significantly many tokens, especially in "Think" mode. To prevent that, if you cap the max_tokens too low, it may stop output prematurely.
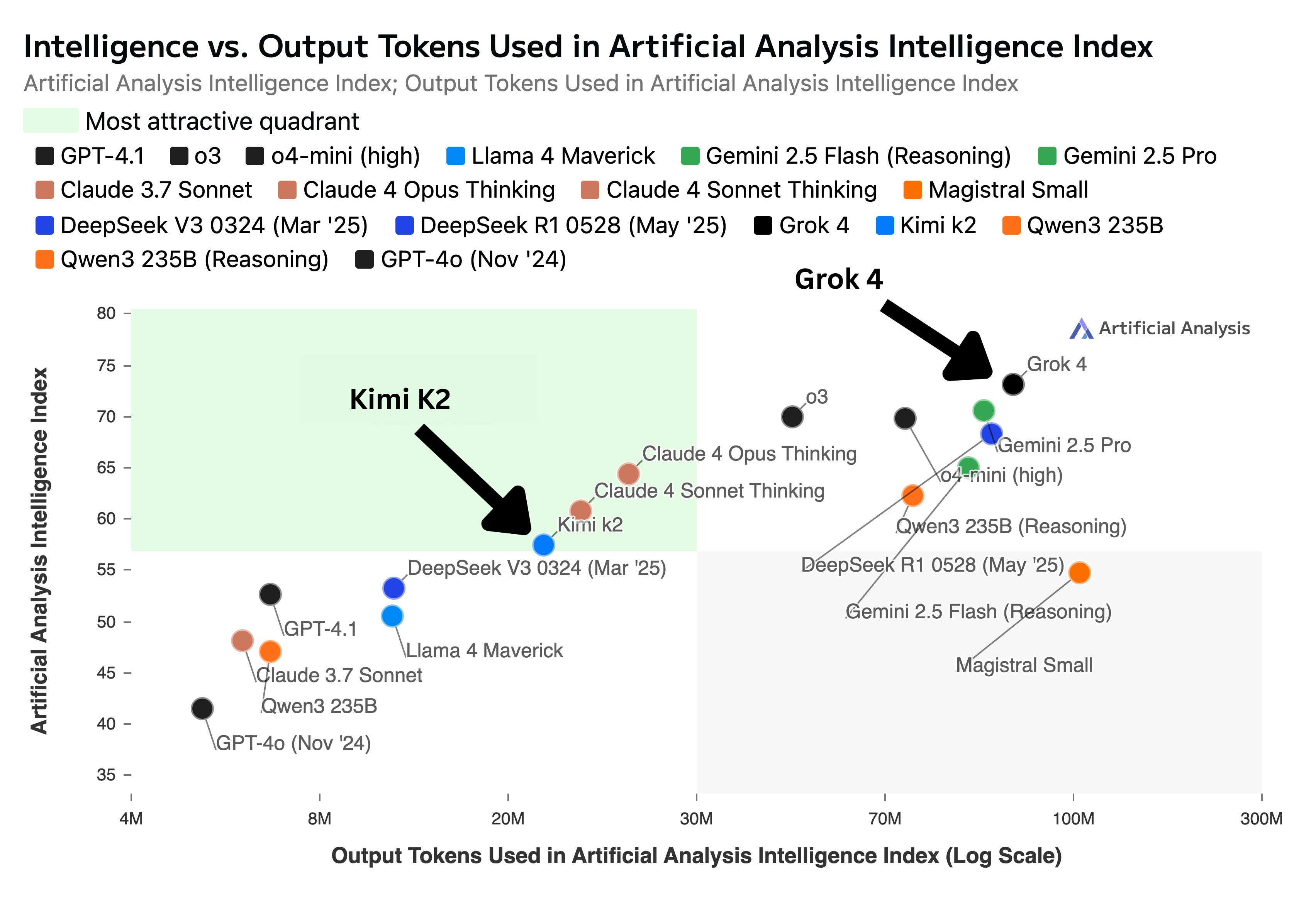
But, in addition to the slower response time, there's a catch with Grok 4 rate limits.
One thing I really hate about this model is the rate limit that's implemented on top of xAI7. Almost every 2-3 requests, you get rate-limited for a few minutes straight. That could be something that throws you off. I didn't notice any rate limits with Kimi K2.
Pricing Breakdown
On average, each task cost me about $5.80 with Grok 4, using approximately 200K output tokens, while with Kimi K2, it cost around $0.40 using about 160K output tokens, which is about one-fourteenth the price of Grok 4.
Grok 4 costs $3 per million input tokens and $15 per million output tokens.
You might notice that $5.80 for 200K tokens seems higher than expected because Grok 4 pricing doubles after 128K output tokens, leading to higher costs for longer outputs.
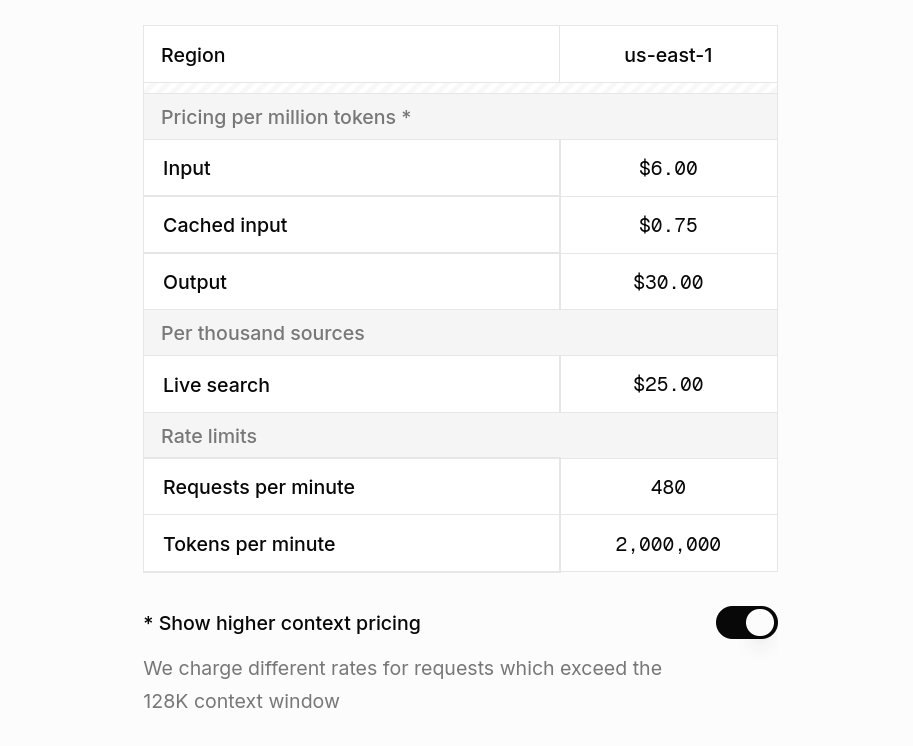
Kimi K2 comes with $0.15 per million input tokens and $2.50 per million output tokens, and it stays flat regardless of the token usage.
Overall Impressions of Each Model
Now, let's look into the overall impression of these models in our entire test and in general, along with the good and bad sides:
Kimi K2
- Ultra cost-efficient: At just $2.50 per million output tokens (plus $0.15 per million input tokens), typical tasks (~160K tokens) cost around $0.40, which is ideal for heavy workflows on a budget.
- Super fast startup: Time to first token is only ~0.5s, making interactions and tool-based workflows feel snappy.
- Built for agentic coding: Great at handling multi-step tasks, API calls, and integrations without complex setup.
- Supports long context: With about a 128K token window, it can handle entire codebases or documentation in one pass.
- Developer-friendly openness: The model is open-source with a permissive license, meaning you can fine-tune or self-host as needed.
- Mild downside: Slower token throughput (~45 tokens/sec) means long responses take longer, and it sometimes over-explains or hallucinates details.
Grok 4
- Reasoning and coding elite: Top-tier scores on tough benchmarks like SWE‑bench, ARC‑AGI, and Humanity’s Last Exam, much better in coding and reasoning compared to Kimi K2.
- Larger context support: Handles up to ~256K tokens (although cost doubles past 128K), better than most models available right now.
- Subtle drawbacks: High output token cost ($15/M, doubling beyond 128K), latency to first token ~11–13s in heavy reasoning modes, and actual runtime speed (~47–75 tokens/sec) can be noticeably slow in long coding sessions.
Quick Stats Comparison
| Metric | Kimi K2 | Grok 4 |
|---|---|---|
| Typical cost/task | ~$0.40 (160K tokens) | ~$5–6 (200K tokens, cost doubles past 128K) |
| Latency (TTFT) | ~0.5s | ~11–16s in reasoning-heavy workflows |
| Output speed | ~45 tokens/sec | ~47–75 tokens/sec (varies by mode) |
| Accuracy & reasoning | Strong for agentic coding workflows | Top-tier in math, logic, and coding benchmarks |
| Context window | ~128K tokens | Up to ~256K tokens |
| Open model | Yes | No |
Conclusion
After looking at these two models and their performance, I'm definitely going with Grok 4, but Kimi K2 is a great option if you're looking for a more cost-efficient model for daily workflows. Grok 4 is much better with code and got the most work done on the first try, though it is costlier compared to Kimi K2, and the rate limit can be really frustrating at times, but it felt much more reliable with implementation, bug fixes, and tool calls.
Grok 4 won me over in this test. That said, both models have their strengths. Kimi K2 stands out for cost-efficiency, while Grok 4 offers superior accuracy and reliability for serious production work. Your choice depends on your workflow and budget.
Related Posts
- Grok 4 Initial Impressions
- Claude Opus 4 vs. Grok 4 Coding Comparison
- Claude Opus 4 vs. Gemini 2.5 Pro
Footnotes
1. Moonshot AI. "Access Kimi K2 via API." https://platform.moonshot.ai ↩
2. NextAuth.js. "Authentication for Next.js Applications." https://next-auth.js.org ↩
3. Pinecone. "Vector Database for Semantic Search and AI Applications." https://www.pinecone.io ↩
4. Composio. "Let AI agents take real-world action with tools and integrations." https://composio.dev ↩
5. Groq. "The Infrastructure For Inference." https://groq.com ↩
6. Anthropic. "Claude 4 Models Pricing." https://www.anthropic.com/pricing#api ↩
7. xAI. "AI Research Company." https://x.ai/ ↩
8. Artificial Analysis. “Kimi K2 Model Card." https://artificialanalysis.ai/models/kimi-k2 ↩
9. Artificial Analysis. "Grok 4 Model Card." https://artificialanalysis.ai/models/grok-4 ↩