Benchmarks Don't Matter — Until They Do
We started this project convinced we were in good shape.
ForgeCode is an open-source coding agent. Our team is three engineers. Engineers on X were posting about how good Claude Code felt. We felt the same about ForgeCode in daily usage — fast, capable, generally reliable. We assumed our production agent would translate directly into strong benchmark performance. We were using the same model everyone else was raving about.
So we ran TermBench 2.0 with one engineer dedicated to the exercise. TermBench is a realistic evaluation suite: agents receive coding tasks in a sandboxed terminal environment and must complete them autonomously under strict time constraints. It tests what actually matters — can the agent navigate an unfamiliar codebase, decompose a problem, call tools correctly, and finish the task before context and budget collapse?
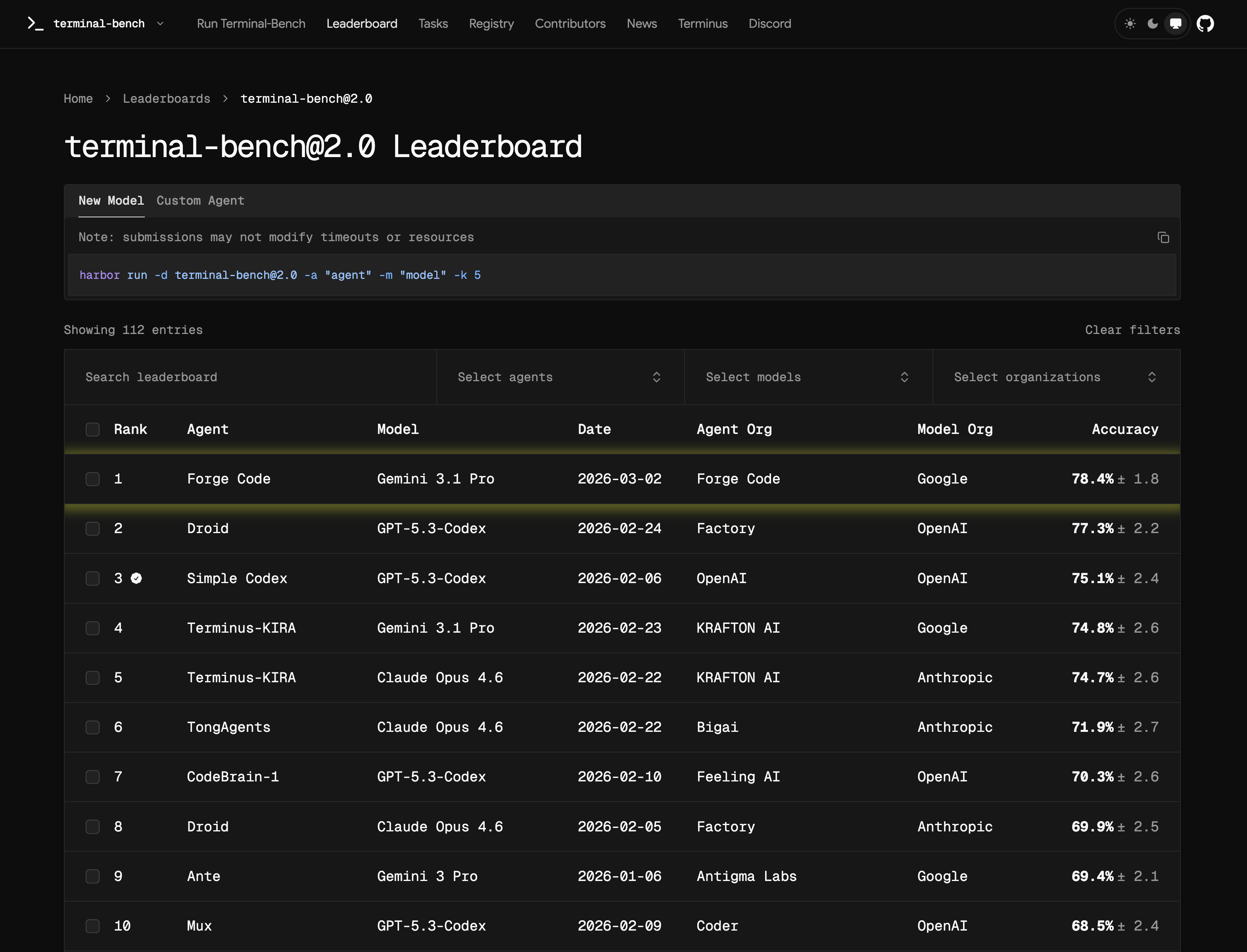
We passed 25% of tests.
This post is about how we diagnosed seven distinct failure modes, fixed them systematically, and reached 78.4% SOTA with gemini-3.1-pro-preview — and why those fixes generalized across models instead of overfitting to a single provider.
Failure Mode 1: Same model, very different performance
Our agent was built for interactive use. It asks clarifying questions when requirements are ambiguous, confirms architectural decisions before proceeding, and checks in with the user when it is uncertain about scope. This is exactly the right behavior in a chat interface.
In a benchmark environment, it is catastrophic.
TermBench tasks are graded on completion. There is no user to answer clarification requests. Every turn spent asking a question is a turn not spent solving the problem. Our agent was failing tasks not because it lacked the intelligence to solve them, but because it was waiting for a human who was never coming.
Fix: We introduced a strict Non-Interactive Mode — a separate runtime profile activated during evaluation:
- System prompt rewritten to prohibit conversational branching and clarification requests
- Tool behavior changed so the agent assumes reasonable defaults and proceeds
- Completion logic tightened so the agent commits to an answer rather than hedging
The model was identical. The runtime configuration changed everything.
Failure Mode 2: Tool descriptions do not guarantee tool correctness
Our assumption: write clear tool descriptions, and models will call them reliably.
Reality: tool misuse was one of the top two failure classes in our initial runs. The failures broke down into three distinct categories:
- Wrong tool selected — agent uses
shellto apply a code edit instead of the structurededittool - Correct tool, wrong argument names — field names close but not matching the schema
- Correct tool, correct arguments, wrong sequencing — tool called before its preconditions are met
These failure classes mix together in aggregate pass rate, which makes them nearly invisible without targeted micro-evals. We had to build separate, single-purpose evaluations that isolate each class per tool, per model. Aggregate scoring alone will not catch this.
Failure Mode 3: Tool and argument naming is a reliability variable, not an aesthetic choice
This one surprised us most.
Models have strong priors from training about what tool calls look like. When your tool names conflict with those priors or your argument names fall outside the patterns the model has seen, error rates climb — not because the model can't understand the description, but because it pattern-matches against training data first.
Concrete example: our file edit tool had generic internal argument names. We renamed them to old_string and new_string — names that appear frequently in training data for this kind of operation. Tool-call error rate on that tool dropped measurably in the same evaluation pass, same model, same prompt.
This is not a small effect. If you are seeing persistent tool-call errors and attribute them entirely to model capability, check your naming first. We address this at the runtime layer — more on that in the ForgeCode Services section below.
Failure Mode 4: Context size is a multiplier on the right entry point, not a substitute for it
The conventional wisdom is that more context means better performance. The nuanced reality is that context only helps once the agent is oriented correctly.
In TermBench tasks, the agent has to explore an unfamiliar codebase. If it finds the right entry point early — the relevant file, function, or module where the actual problem lives — more context helps it reason more deeply from that point. If it never finds the right entry point, more context just means it explores more of the wrong area more thoroughly.
The real bottleneck is entry-point discovery latency, not token count. We built a semantic analysis layer specifically for this — described in the ForgeCode Services section below.
Failure Mode 5: Turn limits punish trajectories, not just wrong answers
The common belief: if the model is smart enough, it will eventually solve the problem.
TermBench is a constrained system. You have a time budget and a context window that accumulates state as the agent works. Each failed tool call, each exploratory dead end, and each redundant read add up. Agents that drift — spending turns on exploration when they should be executing — exhaust their budget without completing the task.
The problem is not that the model cannot solve the task. The problem is that a brilliant but meandering trajectory fails just as definitively as an incorrect one.
Failure Mode 6: Planning tools only work if you enforce them
We had a todo_write tool available from the beginning. It lets the agent maintain an explicit task list — creating items, marking them in-progress, marking them complete. We documented it. We mentioned it in the system prompt. We assumed the agent would use it when appropriate.
It did not use it consistently. The agent would begin multi-step tasks, complete some sub-tasks, lose track of others, and then either repeat work or skip steps entirely — all while the task list sat empty.
The issue is not model capability. It is that optional tools get deprioritized under pressure. When an agent is inside a complex problem, it takes the path of least resistance: the next tool call that seems relevant, not the one that maintains long-term planning state.
Fix: We made todo_write non-optional for decomposed tasks by building low-level evals that assert it:
todo_writemust be called to create items when a multi-step task is identified- Each item must be updated as the agent progresses
- Completion must be explicitly marked
We treated failure to call todo_write as a reliability failure class in our eval suite, not just a stylistic miss. Tasks that decompose correctly but lack tracking state are graded as at-risk.
After integrating this enforcement layer: 38% → 66% pass rate.
Failure Mode 7: TermBench is more about speed than intelligence
This is the one that changed our architecture most significantly.
A very intelligent agent with a slow reasoning trajectory still fails TermBench tasks because the benchmark imposes wall-clock time and turn limits. An agent that spends 40 turns deeply reasoning about the best solution loses to one that finds a good-enough solution in 15 turns.
This forced two structural changes:
Subagent parallelization for low-complexity work. We split tasks by difficulty. Easier, parallelizable subtasks — file reads, pattern searches, routine edits — are delegated to subagents running with low/minimal thinking budget. This keeps the main agent's turn count and latency low on work that does not need deep reasoning.
Progressive thinking policy on the main agent. Rather than running full thinking budget throughout, we applied a tiered policy:
- First 10 assistant messages: very high thinking — this is where the agent forms its plan, identifies the problem structure, and selects its approach. Getting this right is worth the latency.
- Messages 11 onward: low thinking by default — execution phase. The plan is set; the agent should act, not re-deliberate.
- If a verification skill is called: switch back to high thinking — verification is a decision point where wrong answers cascade.
The threshold of 10 messages was calibrated against task complexity distributions in TermBench. Most tasks show the critical decision-making concentrated in early turns; later turns are primarily mechanical execution.
Performance Trajectory
| Phase | Change | Pass Rate |
|---|---|---|
| Baseline | Interactive-first runtime, no planning enforcement | ~25% |
| Stabilization | Non-Interactive mode + tool-call naming + micro-evals | ~38% |
| Planning control | todo_write enforcement via low-level evals | 66% |
| Speed architecture | Subagent parallelization + progressive thinking + skill routing | 78.4% (SOTA) |
Each phase was a targeted intervention against a specific failure class, not a general quality improvement. That specificity is what makes the result reproducible.
Three engineers. An open-source agent. No proprietary model fine-tuning. The #1 position on TermBench 2.0 came from runtime engineering, not scale.
What ForgeCode Services does under the hood
The failure modes above demanded capabilities that go beyond what the open-source agent handles alone. That work became ForgeCode Services — a proprietary runtime layer that sits on top of the open-source ForgeCode agent. It is currently available for free.
1. Semantic entry-point discovery. Before the agent begins exploring, a lightweight semantic pass identifies the most likely starting files and functions based on task description. This converts random codebase exploration into directed traversal.
2. Dynamic skill loading. Skills — specialized instruction sets for particular task types — are loaded only when the task profile requires them. A task involving test-writing loads the testing skill. A task involving debugging does not. This keeps context lean and relevant.
3. Tool-call correction layer. A heuristic + static analysis layer runs before each tool call is dispatched. It checks argument validity, catches common error patterns, and applies corrections where possible. Errors that would fail silently are caught at the dispatch boundary.
4. todo_write enforcement. Task decomposition triggers mandatory planning state updates. The agent is not trusted to remember to update its task list; the runtime asserts it.
5. Reasoning budget control. The progressive thinking policy is applied automatically based on turn count and skill invocation signals. The agent does not manage its own reasoning budget explicitly.
The result generalizes across models because none of these five components depend on model-specific behavior. They are constraints and scaffolding applied at the runtime layer, below the model.
Using benchmarks without fooling yourself
The 78.4% is a result, not the goal. Run TermBench to answer operational questions about your agent system:
- Is your context engine actually efficient under pressure, or does it bloat and stall?
- Are your tools named and described in a way that aligns with model priors across providers?
- Are tools being called when they should be, not just when the model feels like it?
- Does your caching behave correctly under the access patterns a benchmark generates?
TermBench will not answer all of your reliability questions. What it will do is surface failure modes that are invisible in interactive usage, where a patient user compensates for agent drift and tool errors.
The real value is downstream: each TermBench failure class becomes a smaller, cheaper eval that you can run in CI/CD continuously. We now have evals in our pipeline that gate releases on:
- Tool-call correctness rates per tool, per model
todo_writecompliance for decomposed tasks- Entry-point discovery precision
- Skill routing accuracy
These run in minutes. They are not TermBench. But they exist because TermBench showed us exactly where to look.
If your skill engine routes to the wrong skill, the model fails regardless of raw capability. Refining skill selection is one of the highest-leverage improvements available in an agent system that uses skill-based context loading.
What comes next
We are expanding measurement across dimensions that aggregate pass rate obscures:
- Per-tool reliability score by model — different models have different weak tools
- Entry-point discovery latency distribution — not just whether the agent gets there, but how many turns it costs
- Recovery rate after the first tool-call error in a trajectory
- Turn-efficiency curves under tight budgets — does the agent spend turns wisely or drift?
- Cross-model variance on the same task slices — where do models diverge, and why?
The headline is 78.4% SOTA with gemini-3.1-pro-preview — the #1 result on TermBench 2.0, built by a team of three on an open-source agent. The actual output of this work is an agent runtime that holds up under structured pressure and a diagnostic system that tells us specifically what to fix when it does not.
If you're building agents: don't run a benchmark to get a number. Run it to find out which part of your system is lying to you in production.
The ForgeCode agent is open-source at github.com/antinomyhq/forge. ForgeCode Services — the runtime layer that powered the 78.4% result — is proprietary but currently available for free.